Ainulaadne Teenus
Selleks, et saaksime generatiivse tehisintellekti abil teist pilte luua tuleb esmalt treenida tehisintellekti mudel, mis teid “tunneb”. Selleks on vaja teie poolt antud sisendpiltidega algset mudelit kohandada, et see õpiks teid erinevates olukordades kujutama. Hetkel on selle jaoks välja mõeldud neli erinevat meetodit. Meile teadaolevalt oleme hetkel ainus ettevõtte, kes pakub teenusena piltide genereerimist läbi kohandatud tekstuuri inversiooni meetodi. Selle tõttu suudame pakkuda turu kõige kvaliteetsemaid pilte.
Genereerimise Protsess
Mudeli treenimine läbi tekstuuri inversiooni on selle heade tulemuste tõttu ka kõige resursside nõudlikum. Ainuüksi mudeli kohandamiseks on vaja uusima põlvkonna tipptasemel graafikakaarte ja üle tunni treeninguaega. Oleme läbi viinud suurel hulgal eksperimente, et selgitada välja optimaalsed parameetrid ja tingimused mudelite treenimiseks, mida kasutame ka tellimuste täitmisel.
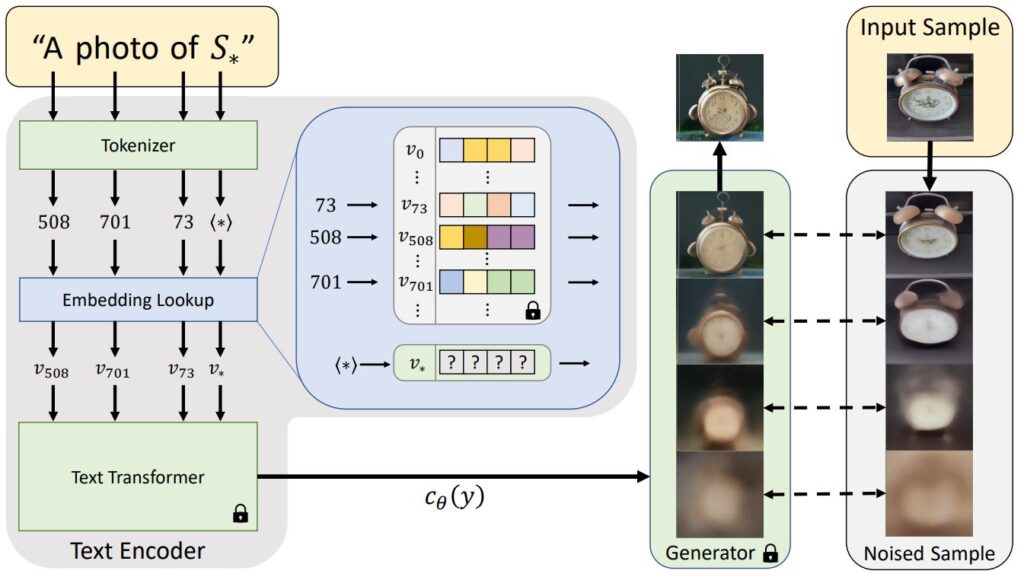
Kunstiline Sisend Ei Kao Kuskile
Kohandatud mudeli loomine on alles väike osa tervest protsessist. Tähtsam ja kunstilisem osa on saadud mudeli kasutamine piltide genereerimiseks. Meie kasutame enamasti text2image meetodit, mis genereerib pildi sisendteksti järgi. Oleme panustanud palju ressursse just kõige paremate sisendtekstide kombinatsioonide välja töötamisse, et saaksime pakkuda enneolematuid tulemusi. Selle käigus oleme ka omandanud ainulaadse oskusteabe ja kompetentsi generatiivse tehisintellekti talitsemiseks.
Baseerume Avatud Lähtekoodiga Tarkvarale
Tehisintellekti mudel, mida kasutatakse piltide genereerimiseks ja kohandatud mudeli aluseks on Stable Diffusion, mille on loonud paljud Müncheni LMU ülikooli ja RunwayML-i teadlased ning mille valmimist on toetanud Emad Mostaque ja teised Stability AI liikmed. Textural Inversion meetodi realisatsioon põhineb masinõppe gigantide koostatud DreamBoothi-le, mille on avatud lähtekoodiga tarkvara kommuun kohandanud ja edasi arendanud. Tehnoloogia on väga algses faasis ja keegi ei oska veel täpselt öelda, milleks see võimeline on.